微信標題不會取,爬取虎嗅5萬篇文章告訴你
不少時候,一篇文章能否得到廣泛的傳播,除了文章本身實打實的質量以外,一個好的標題也至關重要。本文爬取了虎嗅網建站至今共 5 萬條新聞標題內容,助你找到起文章標題的技巧與靈感。同時,分享一些值得關注的文章和作者。
數據抓取、清洗、分析一條龍,感受科技互連網世界的千變萬化。
摘要: 不少時候,一篇文章能否得到廣泛的傳播,除了文章本身實打實的質量以外,一個好的標題也至關重要。本文爬取了虎嗅網建站至今共 5 萬條新聞標題內容,助你找到起文章標題的技巧與靈感。同時,分享一些值得關注的文章和作者。
1. 分析背景
1.1. 為什么選擇虎嗅
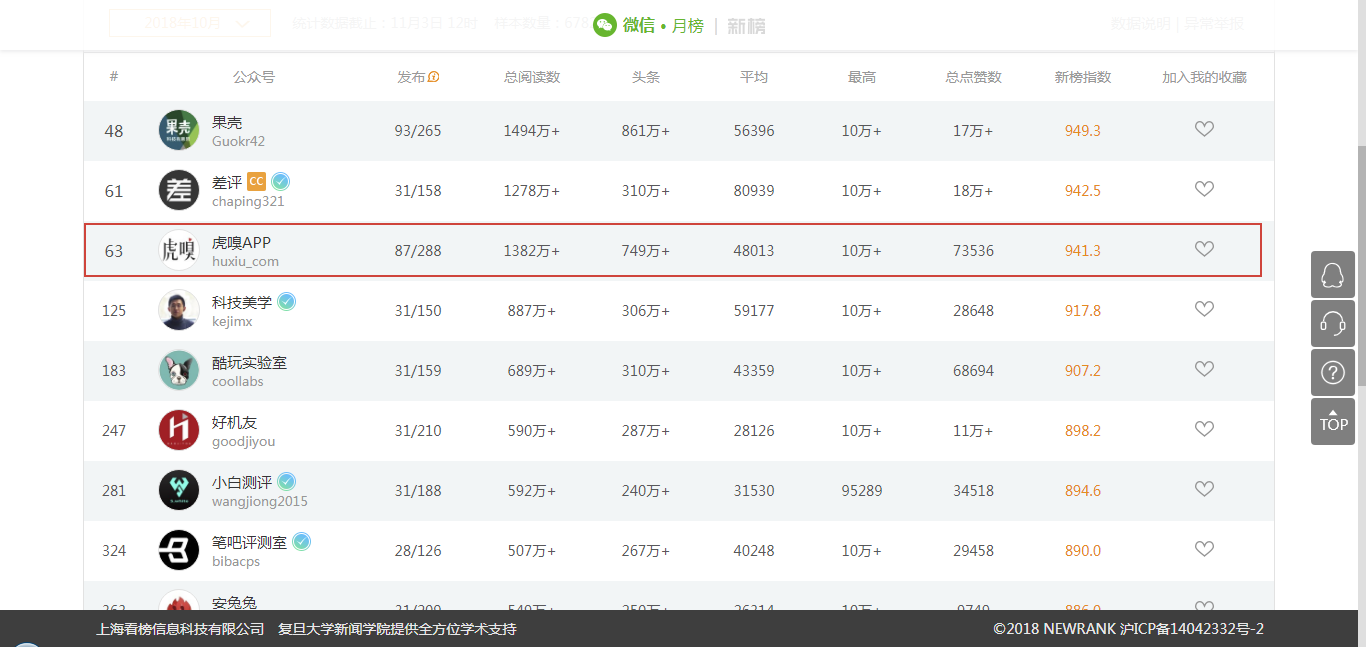
在眾多新媒體網站中,「虎嗅」網的文章內容和質量還算不錯。在「新榜」科技類公眾號排名中,它位居榜單第 3 名,還是比較受歡迎的。所以選擇爬取該網站的文章信息,順便從中了解一下這幾年科技互聯網都出現了哪些熱點信息。
「關于虎嗅」
虎嗅網創辦于 2012 年 5 月,是一個聚合優質創新信息與人群的新媒體平臺。該平臺專注于貢獻原創、深度、犀利優質的商業資訊,圍繞創新創業的觀點進行剖析與交流。虎嗅網的核心,是關注互聯網及傳統產業的融合、明星公司的起落軌跡、產業潮汐的動力與趨勢。
1.2. 分析內容
分析虎嗅網 5 萬篇文章的基本情況,包括收藏數、評論數等
發掘最受歡迎和最不受歡迎的文章及作者
分析文章標題形式(長度、句式)與受歡迎程度之間的關系
展現近些年科技互聯網行業的熱門詞匯
1.3. 分析工具
Python
pyspider
MongoDB
Matplotlib
WordCloud
Jieba
2. 數據抓取
使用 pyspider 抓取了虎嗅網的主頁文章,文章抓取時期為 2012 年建站至 2018 年 11 月 1 日,共計約 5 萬篇文章。抓取 了 7 個字段信息:文章標題、作者、發文時間、評論數、收藏數、摘要和文章鏈接。
2.1. 目標網站分析
這是要爬取的 網頁界面,可以看到是通過 AJAX 加載的。


右鍵打開開發者工具查看翻頁規律,可以看到 URL 請求是 POST 類型,下拉到底部查看 Form Data,表單需提交參數只有 3 項。經嘗試, 只提交 page 參數就能成功獲取頁面的信息,其他兩項參數無關緊要,所以構造分頁爬取非常簡單。
1 | huxiu_hash_code: 39bcd9c3fe9bc69a6b682343ee3f024a |
接著,切換選項卡到 Preview 和 Response 查看網頁內容,可以看到數據都位于 data 字段里。total_page 為 2004,表示一共有 2004 頁的文章內容,每一頁有 25 篇文章,總共約 5 萬篇,也就是我們要爬取的數量。

以上,我們就找到了所需內容,接下來可以開始構造爬蟲,整個爬取思路比較簡單。之前我們也練習過這一類 Ajax 文章的爬取,可以參考:
2.2. pyspider 介紹
和之前文章不同的是,這里我們使用一種新的工具來進行爬取,叫做:pyspider 框架。由國人 binux 大神開發,GitHub Star 數超過 12 K,足以證明它的知名度。可以說,學習爬蟲不能不會使用這個框架。
網上關于這個框架的介紹和實操案例非常多,這里僅簡單介紹一下。
我們之前的爬蟲都是在 Sublime 、PyCharm 這種 IDE 窗口中執行的,整個爬取過程可以說是處在黑箱中,內部運行的些細節并不太清楚。而 pyspider 一大亮點就在于提供了一個可視化的 WebUI 界面,能夠清楚地查看爬蟲的運行情況。

pyspider 的架構主要分為 Scheduler(調度器)、Fetcher(抓取器)、Processer(處理器)三個部分。Monitor(監控器)對整個爬取過程進行監控,Result Worker(結果處理器)處理最后抓取的結果。

我們看看該框架的運行流程大致是怎么樣的:
一個 pyppider 爬蟲項目對應一個 Python 腳本,腳本里定義了一個 Handler 主類。爬取時首先調用 on_start() 方法生成最初的抓取任務,然后發送給 Scheduler。
Scheduler 將抓取任務分發給 Fetcher 進行抓取,Fetcher 執行然后得到 Response、隨后將 Response 發送給 Processer。
Processer 處理響應并提取出新的 URL 然后生成新的抓取任務,然后通過消息隊列的方式通知 Scheduler 當前抓取任務執行情況,并將新生成的抓取任務發送給 Scheduler。如果生成了新的提取結果,則將其發送到結果隊列等待 Result Worker 處理。
Scheduler 接收到新的抓取任務,然后查詢數據庫,判斷其如果是新的抓取任務或者是需要重試的任務就繼續進行調度,然后將其發送回 Fetcher 進行抓取。
不斷重復以上工作、直到所有的任務都執行完畢,抓取結束。
抓取結束后、程序會回調 on_finished() 方法,這里可以定義后處理過程。
該框架比較容易上手,網頁右邊是代碼區,先定義類(Class)然后在里面添加爬蟲的各種方法(也可以稱為函數),運行的過程會在左上方顯示,左下方則是輸出結果的區域。
這里,分享幾個不錯的教程以供參考:
GitHub 項目地址:https://github.com/binux/pyspider
官方主頁:http://docs.pyspider.org/en/latest/
pyspider 中文網:http://www.pyspider.cn/page/1.html
pyspider 爬蟲原理剖析:http://python.jobbole.com/81109/
pyspider 爬淘寶圖案例實操:https://cuiqingcai.com/2652.html
安裝好該框架后,下面我們可以就開始爬取了。
2.3. 抓取數據
CMD 命令窗口執行:pyspider all 命令,然后瀏覽器輸入:http://localhost:5000/ 就可以啟動 pyspider 。
點擊 Create 新建一個項目,Project Name 命名為:huxiu,因為要爬取的 URL 是 POST 類型,所以這里可以先不填寫,之后可以在代碼中添加,再次點擊 Creat 便完成了該項目的新建。

新項目建立好后會自動生成一部分模板代碼,我們只需在此基礎上進行修改和完善,然后就可以運行爬蟲項目了。現在,簡單梳理下代碼編寫步驟。

1 | from pyspider.libs.base_handler import * |
這里,首先定義了一個 Handler 主類,整個爬蟲項目都主要在該類下完成。 接著,可以將爬蟲基本的一些基本配置,比如 Headers、代理等設置寫在下面的 crawl_config 屬性中。(如果你還沒有習慣從函數(def)轉換到類(Class)的代碼寫法,那么需要先了解一下類的相關知識,之后我也會單獨用一篇文章介紹一下。)
下面的 on_start() 方法是程序的入口,也就是說程序啟動后會首先從這里開始運行。首先,我們將要爬取的 URL傳入 crawl() 方法,同時將 URL 修改成虎嗅網的:https://www.huxiu.com/v2_action/article_list。由于 URL 是 POST 請求,所以我們還需要增加兩個參數:method 和 data。method 表示 HTTP 請求方式,默認是 GET,這里我們需要設置為 POST;data 是 POST 請求表單參數,只需要添加一個 page 參數即可。
接著,通過 callback 參數定義一個 index_page() 方法,用來解析 crawl() 方法爬取 URL 成功后返回的 Response 響應。在后面的 index_page() 方法中,可以使用 PyQuery 提取響應中的所需內容。具體提取方法如下:
1 | import json |
這里,網頁返回的 Response 是 json 格式,待提取的信息存放在其中的 data 鍵值中,由一段 HTML 代碼構成。我們可以使用 response.json[‘data’] 獲取該 HTML 信息,接著使用 PyQuery 搭配 CSS 語法提取出文章標題、鏈接、作者等所需信息。這里使用了列表生成式,能夠精簡代碼并且轉換為方便的 list 格式,便于后續存儲到 MongoDB 中。我們輸出并查看一下第 2 頁的提取結果:
1 | # 由25個 dict 構成的 list |
可以看到,成功得到所需數據,然后就可以保存了,可以選擇輸出為 CSV、MySQL、MongoDB 等方式,這里我們選擇保存到 MongoDB 中。
1 | import pandas as pd |
上面,定義了一個 on_result() 方法,該方法專門用來獲取 return 的結果數據。這里用來接收上面 index_page() 返回的 data 數據,在該方法里再定義一個存儲到 MongoDB 的方法就可以保存到 MongoDB 中。關于數據如何存儲到 MongoDB 中,我們在之前的 一篇文章 中有過介紹,如果忘記了可以回顧一下。
下面,我們來測試一下整個爬取和存儲過程。點擊左上角的 run 就可以順利運行單個網頁的抓取、解析和存儲,結果如下:

上面完成了單頁面的爬取,接下來,我們需要爬取全部 2000 余頁內容。
需要修改兩個地方,首先在 on_start() 方法中將 for 循環頁數 3 改為 2002。改好以后,如果我們直接點擊 run ,會發現還是只能爬取第 2 頁的結果。這是因為,pyspider 以 URL的 MD5 值作為 唯一 ID 編號,ID 編號相同的話就視為同一個任務,便不會再重復爬取。由于 GET 請求的 分頁URL 通常是有差異的,所以 ID 編號會不同,也就自然能夠爬取多頁。但這里 POST 請求的分頁 URL 是相同的,所以爬完第 2 頁,后面的頁數便不會再爬取。
那有沒有解決辦法呢? 當然是有的,我們需要重新寫下 ID 編號的生成方式,方法很簡單,在 on_start() 方法前面添加下面 2 行代碼即可:
1 | def get_taskid(self,task): |
這樣,我們再點擊 run 就能夠順利爬取 2000 頁的結果了,我這里一共抓取了 49,996 條結果,耗時 2 小時左右完成。

以上,就完成了數據的獲取。有了數據我們就可以著手分析,不過這之前還需簡單地進行一下數據的清洗、處理。
3. 數據清洗處理
首先,我們需要從 MongoDB 中讀取數據,并轉換為 DataFrame。
1 | client = pymongo.MongoClient(host='localhost', port=27017) |
下面我們看一下數據的總體情況,可以看到數據的維度是 49996 行 × 8 列。發現多了一列無用的 _id 需刪除,同時 name 列有一些特殊符號,比如? 需刪除。另外,數據格式全部為 Object 字符串格式,需要將 comment 和 favorites 兩列更改為數值格式、 write_time 列更改為日期格式。
1 | print(data.shape) # 查看行數和列數 |
代碼實現如下:
1 | # 刪除無用_id列 |
下面,我們看一下數據是否有重復,如果有,那么需要刪除。
1 | # 判斷整行是否有重復值 |
然后,我們再增加兩列數據,一列是文章標題長度列,一列是年份列,便于后面進行分析。
1 | data['title_length'] = data['title'].apply(len) |
以上,就完成了基本的數據清洗處理過程,針對這 9 列數據可以開始進行分析了。
4. 描述性數據分析
通常,數據分析主要分為四類: 「描述型分析」、「診斷型分析」「預測型分析」「規范型分析」。「描述型分析」是用來概括、表述事物整體狀況以及事物間關聯、類屬關系的統計方法,是這四類中最為常見的數據分析類型。通過統計處理可以簡潔地用幾個統計值來表示一組數據地集中性(如平均值、中位數和眾數等)和離散型(反映數據的波動性大小,如方差、標準差等)。
這里,我們主要進行描述性分析,數據主要為數值型數據(包括離散型變量和連續型變量)和文本數據。
4.1. 總體情況
先來看一下總體情況。
1 | print(data.describe()) |
這里,使用了 data.describe() 方法對數值型變量進行統計分析。從上面可以簡要得出以下幾個結論:
讀者的評論和收藏熱情都不算太高,大部分文章(75 %)的評論數量為十幾條,收藏數量不過幾十個。這和一些微信大 V 公眾號動輒百萬級閱讀、數萬級評論和收藏量相比,虎嗅網的確相對小眾一些。不過也正是因為小眾,也才深得部分人的喜歡。
評論數最多的文章有 2376 條,收藏數最多的文章有 1113 個收藏量,說明還是有一些潛在的比較火或者質量比較好的文章。
最長的文章標題長達 224 個字,大部分文章標題長度在 20 來個字左右,所以標題最好不要太長或過短。
對于非數值型變量(name、write_time),使用 describe() 方法會產生另外一種匯總統計。
1 | print(data['name'].describe()) |
unique 表示唯一值數量,top 表示出現次數最多的變量,freq 表示該變量出現的次數,所以可以簡單得出以下幾個結論:
在文章來源方面,3162 個作者貢獻了這 5 萬篇文章,其中自家官網「虎嗅」寫的數量最多,超過了 1 萬篇,這也很自然。
在文章發表時間方面,最早的一篇文章來自于 2012年 4 月 3 日。 6 年多時間,發文數最多的 1 天 是 2014 年 7 月 10 日,一共發了 274 篇文章。
4.2. 不同時期文章發布的數量變化

可以看到 ,以季度為時間尺度的6 年間,前幾年發文數量比較穩定,大概在1750 篇左右,個別季度數量激增到 2000 篇以上。2016 年之后文章開始增加到 2000 篇以上,可能跟網站知名度提升有關。首尾兩個季度日期不全,所以數量比較少。
具體代碼實現如下:
1 | def analysis1(data): |
4.3. 文章收藏量 TOP 10
接下來,到了我們比較關心的問題:幾萬篇文章里,到底哪些文章寫得比較好或者比較火?
| 序號 | title | favorites | comment |
|---|---|---|---|
| 1 | 讀完這10本書,你就能站在智商鄙視鏈的頂端了 | 1113 | 13 |
| 2 | 京東打臉央視:你所謂的翻新iPhone均為正品,我們保留向警方報案的權利 | 867 | 10 |
| 3 | 離職創業?先讀完這22本書再說 | 860 | 9 |
| 4 | 貨幣如水,覆水難收 | 784 | 39 |
| 5 | 自殺經濟學 | 778 | 119 |
| 6 | 2016年已經起飛的5只黑天鵝,都在羅振宇這份跨年演講全文里 | 774 | 39 |
| 7 | 真正強大的商業分析能力是怎樣煉成的? | 746 | 18 |
| 8 | 騰訊沒有夢想 | 705 | 32 |
| 9 | 段永平連答53問,核心是“不為清單” | 703 | 27 |
| 10 | 王健林的滑鐵盧 | 701 | 92 |
此處選取了「favorites」(收藏數量)作為衡量標準。畢竟,一般好的文章,我們都會有收藏的習慣。
第一名「讀完這10本書,你就能站在智商鄙視鏈的頂端了 」以 1113 次收藏位居第一,并且遙遙領先于后者,看來大家都懷有「想早日攀上人生巔峰,一覽眾人小」的想法啊。打開這篇文章的鏈接,文中提到了這幾本書:《思考,快與慢》、《思考的技術》、《麥肯錫入職第一課:讓職場新人一生受用的邏輯思考力》等。一本都沒看過,看來這輩子是很難登上人生巔峰了。
發現兩個有意思的地方。
第一,文章標題都比較短小精煉。
第二,文章收藏量雖然比較高,但評論數都不多,猜測這是因為 大家都喜歡做伸手黨?
4.4. 歷年文章收藏量 TOP3
在了解文章的總體排名之后,我們來看看歷年的文章排名是怎樣的。這里,每年選取了收藏量最多的 3 篇文章。
| year | title | favorites |
|---|---|---|
| 2012 | 產品的思路——來自騰訊張小龍的分享(全版) | 187 |
| Fab CEO:創辦四家公司教給我的90件事 | 163 | |
| 張小龍:微信背后的產品觀 | 162 | |
| 2013 | 創業者手記:我所犯的那些入門錯誤 | 473 |
| 馬化騰三小時講話實錄:千億美金這個線,其實很恐怖 | 391 | |
| 雕爺親身談:白手起家的我如何在30歲之前賺到1000萬。讀《MBA教不了的創富課》 | 354 | |
| 2014 | 85后,突變的一代 | 528 |
| 雕爺自述:什么是我做餐飲時琢磨、而大部分“外人”無法涉獵的思考? | 521 | |
| 據說這40張PPT是螞蟻金服的內部培訓資料…… | 485 | |
| 2015 | 讀完這10本書,你就能站在智商鄙視鏈的頂端了 | 1113 |
| 京東打臉央視:你所謂的翻新iPhone均為正品,我們保留向警方報案的權利 | 867 | |
| 離職創業?先讀完這22本書再說 | 860 | |
| 2016 | 蝗蟲般的刷客大軍:手握千萬手機號,分秒間薅干一家平臺 | 554 |
| 準CEO必讀的這20本書,你讀過幾本? | 548 | |
| 運營簡史:一文讀懂互聯網運營的20年發展與演變 | 503 | |
| 2017 | 2016年已經起飛的5只黑天鵝,都在羅振宇這份跨年演講全文里 | 774 |
| 真正強大的商業分析能力是怎樣煉成的? | 746 | |
| 王健林的滑鐵盧 | 701 | |
| 2018 | 貨幣如水,覆水難收 | 784 |
| 自殺經濟學 | 778 | |
| 騰訊沒有夢想 | 705 |

可以看到,文章收藏量基本是逐年遞增的,但 2015 年的 3 篇文章的收藏量卻是最高的,包攬了總排名的前 3 名,不知道這一年的文章有什么特別之處。
以上只羅列了一小部分文章的標題,可以看到標題起地都蠻有水準的。關于標題的重要性,有這樣通俗的說法:「一篇好文章,標題占一半」,一個好的標題可以大大增強文章的傳播力和吸引力。文章標題雖只有短短數十字,但要想起好,里面也是很有很多技巧的。
好在,這里提供了 5 萬個標題可以參考。如需,可以在公眾號后臺回復「虎嗅」得到這份 CSV 文件。
代碼實現如下:
1 | def analysis2(data): |
4.4.1. 最高產作者 TOP20
上面,我們從收藏量指標進行了分析,下面,我們關注一下發布文章的作者(個人/媒體)。前面提到發文最多的是虎嗅官方,有一萬多篇文章,這里我們篩除官媒,看看還有哪些比較高產的作者。

可以看到,前 20 名作者的發文量差距都不太大。發文比較多的有「娛樂資本論」、「Eastland」、「發條橙子」這類媒體號;也有虎嗅官網團隊的作者:發條橙子、周超臣、張博文等;還有部分獨立作者:假裝FBI、孫永杰等。可以嘗試關注一下這些高產作者。
代碼實現如下:
1 | def analysis3(data): |
4.4.2. 平均文章收藏量最多作者 TOP 10
我們關注一個作者除了是因為文章高產以外,可能更看重的是其文章水準。這里我們選擇「文章平均收藏量」(總收藏量/文章數)這個指標,來看看文章水準比較高的作者是哪些人。
這里,為了避免出現「某作者只寫了一篇高收藏率的文章」這種不能代表其真實水準的情況,我們將篩選范圍定在至少發布過 5 篇文章的作者們。
| name | total_favorites | ariticls_num | avg_favorites |
|---|---|---|---|
| 重讀 | 1947 | 6 | 324 |
| 樓臺 | 2302 | 8 | 287 |
| 彭縈 | 2487 | 9 | 276 |
| 曹山石 | 1187 | 5 | 237 |
| 飯統戴老板 | 7870 | 36 | 218 |
| 筆記俠 | 1586 | 8 | 198 |
| 辯手李慕陽 | 11989 | 62 | 193 |
| 李錄 | 2370 | 13 | 182 |
| 高曉松 | 889 | 5 | 177 |
| 寧南山 | 2827 | 16 | 176 |
可以看到,前 10 名作者包括:遙遙領先的 重讀、兩位高產又有質量的 辯手李慕陽 和 飯統戴老板 ,還有大眾比較熟悉的 高曉松、寧南山 等。
如果你將這份名單和上面那份高產作者名單進行對比,會發現他們沒有出現在這個名單中。相比于數量,質量可能更重要吧。
下面,我們就來看看排名第一的 重讀 都寫了哪些高收藏量文章。
| order | title | favorites | write_time |
|---|---|---|---|
| 1 | 我采訪出200多萬字素材,還原了阿里系崛起前傳 | 231 | 2018/10/31 |
| 2 | 阿里史上最強人事地震回顧:中供鐵軍何以被生生解體 | 494 | 2018/4/9 |
| 3 | 馬云“斬”衛哲:復原阿里史上最震撼的人事地震 | 578 | 2018/3/15 |
| 4 | 重讀一場馬云發起、針對衛哲的批斗會 | 269 | 2017/8/31 |
| 5 | 阿里“中供系”前世今生:馬云麾下最神秘的子弟兵 | 203 | 2017/5/10 |
| 6 | 揭秘馬云麾下最神秘的子弟兵:阿里“中供系”的前世今生 | 172 | 2017/4/26 |
居然寫的都是清一色關于馬老板家的文章。
了解了前十名作者之后,我們順便也看看那些處于最后十名的都是哪些作者。
| name | total_favorites | ariticls_num | avg_favorites |
|---|---|---|---|
| 于斌 | 25 | 11 | 2 |
| 朝克圖 | 33 | 23 | 1 |
| 東風日產 | 24 | 13 | 1 |
| 董曉常 | 14 | 8 | 1 |
| 蔡鈺 | 31 | 16 | 1 |
| 馬繼華 | 12 | 11 | 1 |
| angeljie | 7 | 5 | 1 |
| 薛開元 | 6 | 6 | 1 |
| pookylee | 15 | 24 | 0 |
| Yang Yemeng | 0 | 7 | 0 |
一對比,就能看到他們的文章收藏量就比較寒磣了。尤其好奇最后一位作者 Yang Yemeng ,他寫了 7 篇文章,竟然一個收藏都沒有。
來看看他究竟寫了些什么文章。

原來寫的全都是英文文章,看來大家并不太鐘意閱讀英文類的文章啊。
具體實現代碼:
1 | def analysis4(data): |
4.5. 文章評論數最多 TOP10
說完了收藏量。下面,我們再來看看評論數量最多的文章是哪些。
| order | title | comment | favorites |
|---|---|---|---|
| 1 | 喜瓜2.0—明星社交應用的中國式引進與創新 | 2376 | 3 |
| 2 | 百度,請給“兒子們”好好起個名字 | 1297 | 9 |
| 3 | 三星S5為什么對鳳凰新聞客戶端下注? | 1157 | 1 |
| 4 | 三星Tab S:馬是什么樣的馬?鞍又是什么樣的鞍? | 951 | 0 |
| 5 | 三星,正在重塑你的營銷觀 | 914 | 1 |
| 6 | 馬化騰,你就把微信賣給運營商得了! | 743 | 20 |
| 7 | 【文字直播】羅永浩 VS 王自如 網絡公開辯論 | 711 | 33 |
| 8 | 看三星Hub如何推動數字內容消費變革 | 684 | 1 |
| 9 | 三星要重新定義軟件與內容商店新模式,SO? | 670 | 0 |
| 10 | 三星Hub——數字內容交互新模式 | 611 | 0 |
基本上都是和 三星 有關的文章,這些文章大多來自 2014 年,那幾年 三星 好像是挺火的,不過這兩年國內基本上都見不到三星的影子了,世界變化真快。
發現了兩個有意思的現象。
第一,上面關于 三星 和前面 阿里 的這些批量文章,它們「霸占」了評論和收藏榜,結合知乎上曾經的一篇關于介紹虎嗅這個網站的文章:虎嗅網其實是這樣的 ,貌似能發現些微妙的事情。
第二,這些文章評論數和收藏數兩個指標幾乎呈極端趨勢,評論量多的文章收藏量卻很少,評論量少的文章收藏量卻很多。
我們進一步觀察下這兩個參數的關系。

可以看到,大多數點都位于左下角,意味著這些文章收藏量和評論數都比較低。但也存在少部分位于上方和右側的異常值,表明這些文章呈現 「多評論、少收藏」或者「少評論、多收藏」的特點。
4.6. 文章標題長度
下面,我們再來看看文章標題的長度和收藏量之間有沒有什么關系。

大致可以看出兩點現象:
第一,收藏量高的文章,他們的標題都比較短(右側的部分散點)。
第二,標題很長的文章,它們的收藏量都非常低(左邊形成了一條垂直線)。
看來,文章起標題時最好不要起太長的。
實現代碼如下:
1 | def analysis5(data): |
文章標題形式
下面,我們看看作者在起文章標題的時候,在標點符號方面有沒有什么偏好。
可以看到,五萬篇文章中,大多數文章的標題是陳述性標題。三分之一(34.8%) 的文章標題使用了問號「?」,而僅有 5% 的文章用了嘆號「!」。通常,問號會讓人們產生好奇,從而想去點開文章;而嘆號則會帶來一種緊張或者壓迫感,使人不太想去點開。所以,可以嘗試多用問號而少用嘆號。

4.7. 文本分析
最后,我們從這 5 萬篇文章中的標題和摘要中,來看看虎嗅網的文章主要關注的都是哪些主題領域。
這里首先運用了 jieba 分詞包對標題進行了分詞,然后用 WordCloud 做成了詞云圖,因虎嗅網含有「虎」字,故選取了一張老虎頭像。(關于 jieba 和 WordCloud 兩個包,之后再詳細介紹)

可以看到文章的主題內容側重于:互聯網、知名公司、電商、投資這些領域。這和網站本身對外宣傳的核心內容,即「關注互聯網與移動互聯網一系列明星公司的起落軌跡、產業潮汐的動力與趨勢,以及互聯網與移動互聯網如何改造傳統產業」大致相符合。
實現代碼如下:
1 | def analysis6(data): |
上面的關鍵詞是這幾年總體的概況,而科技互聯網行業每年的發展都是不同的,所以,我們再來看看歷年的一些關鍵詞,透過這些關鍵詞看看這幾年互聯網行業、科技熱點、知名公司都有些什么不同變化。

可以看到每年的關鍵詞都有一些相同之處,但也不同的地方:
中國互聯網、公司、蘋果、騰訊、阿里等這些熱門關鍵詞一直都是熱門,這幾家公司真是穩地一批啊。
每年會有新熱點涌現:比如 2013 年的微信(剛開始火)、2016 年的直播(各大直播平臺如雨后春筍般出現)、2017年的 iPhone(上市十周年)、2018年的小米(上市)。
不斷有新的熱門技術出現:2013 - 2015 年的 O2O、2016 年的 VR、2017 年的 AI 、2018 年的「區塊鏈」。這些科技前沿技術也是這幾年大家口耳相傳的熱門詞匯。
通過這一幅圖,就看出了這幾年科技互聯網行業、明星公司、熱點信息的風云變化。
5. 小結
本文簡要分析了虎嗅網 5 萬篇文章信息,大致了解了近些年科技互聯網的千變萬化。
發掘了那些優秀的文章和作者,能夠節省寶貴的時間成本。
一篇文章要想傳播廣泛,文章本身的質量和標題各占一半,文中的5 萬個標題相信能夠帶來一些靈感。
本文尚未做深入的文本挖掘,而文本挖掘可能比數據挖掘涵蓋的信息量更大,更有價值。進行這些分析需要機器學習和深度學習的知識,待后期學習后再來補充。

想要了解更多關于用戶運營的干貨知識,請繼續關注135編輯器。
立即登錄